Come il protocollo DNS visto nella lezione precedente, anche protocollo HTTP opera al livello più alto nello stack di protocolli TCP/IP e cioè al livello di applicazione. HTTP sta per Hypertext Transfer Protocol e come, suggerisce il nome, il suo scopo è essenzialmente quello di assicurare il corretto trasferimento di file (e altri dati, chiamati collettivamente risorse) in rete: pagine html, immagini etc.
Tipicamente HTTP viene utilizzato da un browser (http client) per recuperare una pagina web su un host remoto (http server).
Ogni messaggio (PDU) del protocollo HTTP (sia che si tratti di una richiesta del client che di una risposta del server) ha lo stesso formato generale mostrato in figura:
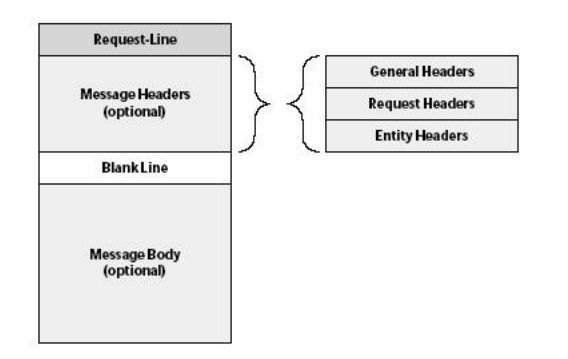
La figura seguente mostra invece il tipico scambio di messaggi fra un client (browser) e un server web per la richiesta di una pagina:
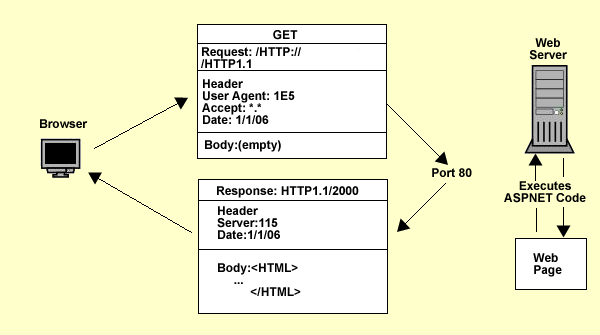
Osserviamo che anche in questo caso, come già abbiamo visto per il protocollo DNS, c'è una parte di intestazione (header) e una parte di dati (body). L'header specifica il tipo di PDU (di GET, cioè di richiesta, oppure di Response, cioè di risposta) e altre informazioni riguardo alla pagina richiesta, alla sua URL, al tipo di browser usato eccetera. Il body invece è vuoto nella PDU di richiesta, mentre nella PDU di risposta contiene il codice HTML della pagina da visualizzare.
Ogni richiesta HTTP incomincia sempre con una linea di richiesta. Questa linea di testo è composta da tre campi, separati da spazi:
- Metodo:
Il metodo indica l'operazione che dev'essere eseguita sulla risorsa indicata dalla URL. Per esempio il metodo GET indica che si vuole ottenere la risorsa, mentre POST indica che l'utente vuole inviare dati (es. un file) al server;
- URL:
Indica l'URL della risorsa (pagina web, immagine etc.) che si vuole richiedere;
- Versione HTTP:
Indica la versione del protocollo HTTP utilizzata.
Esempio: GET /i-corsi.html HTTP/1.1
Consideriamo di nuovo l'esempio in cui venga richiesta la pagina i-corsi.html sul server www.majorana.gov.it. La PDU di richiesta della pagina potrebbe essere fatta in questo modo:
GET /i-corsi.html HTTP/1.1
Host: www.majorana.gov.it
Connection: keep-alive
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
User-Agent: Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.111 Safari/537.36
Referer: http://www.majorana.gov.it/
Accept-Encoding: gzip,deflate,sdch
Accept-Language: it,en;q=0.8,en-US;q=0.6,pt;q=0.4,ru;q=0.2
Cookie: joomla_fs=80; joomla_skin=white; 039c8853bd72d135b833dee4644dbb9f=k2nokfkju9ndupg2g7c0blsjb4
In questo caso, come abbiamo detto prima, trattandosi di una GET, la parte dati (body) è assente e tutto quanto mostrato qui sopra fa parte dell'header.
La PDU viene passata al livello sottostante (protocollo TCP)
Nel caso del protocollo HTTP i messaggi vengono passati al protocollo TCP che lavora sul livello di trasporto sottostante. Riprendendo l'analogia con la lettera, la PDU di richiesta pagina (GET) può essere pensata come una lettera, dove l'intestazione (header) è scritta sulla busta e il body è il contenuto (in questo caso particolare in realtà la busta è vuota, poiché nella richiesta pagina non c'è body).
Questa busta viene passata al livello TCP con l'indicazione
- dell'indirizzo IP del server HTTP da contattare e quella del PC che ha effettuato la richiesta
- la porta che identifica il servizio HTTP sul server (si tratta di una porta standard, 80) e la porta dinamicamente assegnata al browser.
Con la solita analogia dei post-it, possiamo pensare il passaggio della PDU al livello sottostante in questo modo:

Il livello TCP recapiterà la risposta al browser quando questa arriverà dal server. Il browser (o più esattamente, il particolare processo che ha effettuato la richiesta) viene identificato per mezzo di un numero di porta assegnato automaticamente dal sistema operativo (porta non standard), così come abbiamo già visto parlando del protocollo DNS.
L'header del messaggio di risposta dal server ha una struttura di questo tipo:
HTTP/1.1 200 OK Date: Mon, 27 Jul 2014 12:28:53 GMT Server: Apache/2.2.14 (Win32) Last-Modified: Wed, 22 Jul 2014 19:15:56 GMT ETag: "34aa387-d-1568eb00" Vary: Authorization,Accept Accept-Ranges: bytes Content-Length: 571 Content-Type: text/html Connection: Closed
<?xml version="1.0" encoding="utf-8"?><!DOCTYPE html
PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="it-it" lang="it-it" dir="ltr">
<head>
<meta name="language" content="it-it" />
....
Nel caso della risposta, dopo l'header (in rossi) c'è una parte di body che contiene il codice html della pagina richiesta (mostrato solo in parte nell'esempio qui sopra).
In realtà le cose sono più complicate di quelle mostrate nel nostro esempio, in quanto una pagina web non è solitamente composta da un solo file html, ma spesso contiene riferimenti ad altre risorse (es. file di immagini, fogli stile, video etc.) che devono essere scaricati per poter visualizzare correttamente la pagina. Si tenga inoltre conto del fatto che tali risorse potrebbero essere ospitate anche su server host diversi da quello della pagina web (per esempio le immagini potrebbero essere linkate su altri server in Internet).
La prima versione di HTTP (HTTP/1.0 ) richiedeva ai client di stabilire una connessione TCP separata per ogni richiesta. Il browser in questo caso deve dunque effettuare una richiesta separata per ciascuna delle risorse che deve acquisire (e in alcuni casi dovrà anche contattare il server DNS per risolvere URL sconosciute), seguendo le stesse modalità viste prima nel caso della richiesta del file HTML. In pratica deve inviare una GET per ogni risorsa richiesta e per ogni risorsa deve attendere una risposta dal server.
Ecco nei dettagli ciò che accade:
- Il client HTTP inizia una connessione TCP al server
www.majorana.gov.it.
- La porta numero 80 è usata come numero di default della
porta a cui il server HTTP ascolterà i client HTTP che
vogliono recuperare i documenti usando l'HTTP.
- Il client HTTP invia un messaggio di richiesta HTTP al
server attraverso la connessione TCP che è stata stabilita
al passo 1. Il messaggio di richiesta include il nome del percorso
/i-corsi.html
- Il server riceve il messaggio di richiesta, trova
l'oggetto i-corsi.html, lo incapsula all'interno di una
PDU di risposta e invia quest'ultima al client.
- Il client HTTP riceve il messaggio di risposta. La
connessione TCP si conclude. Il messaggio indica che
l'oggetto incapsulato è un file HTML. Il client estrae il
file dal messaggio di risposta, analizza il file HTML e
trova i riferimenti ad altre risorse (es. immagini).
- I primi quattro passi vengono quindi ripetuti per ciascuno delle risorse cui si fa riferimento.
La versione attuale 1.1 del protocollo HTTP ha eliminato il problema delle connessioni multiple TCP con una caratteristica chiamata "persistenza" o "permanenza". Essa abilita un client a continuare ad usare una connessione TCP esistente dopo che la sua iniziale richiesta è stata soddisfatta dal server.
Con questo tipo di connessione, il server lascia aperta la connessione TCP dopo aver spedito la risposta. Le successive richieste e risposte fra gli stessi client e server possono essere inviate sull'identica connessione. In particolare, un'intera pagina Web (comprensiva ad esempio di testo, immagini e altri file) può essere spedita su una singola connessione TCP permanente; inoltre, pagine Web multiple residenti sullo stesso server possono essere spedite sulla stessa connessione TCP permanente. Tipicamente, il server HTTP chiude una connessione quando non è usata per un certo tempo (intervallo di timeout), che spesso è configurabile.
Sito realizzato in base al template offerto da
http://www.graphixmania.it
