L'algoritmo di Huffman è una delle tecniche di compressione lossless statistica più note. Come tutte le tecniche statistiche si basa su un'analisi di frequenza/probabilità sul file da comprimere e, essendo una tecnica lossless, consente la compressione senza perdita di informazioni.
L'algoritmo di Huffman si basa sull'idea di utilizzare codici brevi (con meno bit) per rappresentare i codici più frequenti all'interno dei dati e di usare invece codici lunghi (con più bit) per i dati meno frequenti. Facciamo un semplice esempio per vedere come funziona.
Vediamo un esempio pratico di applicazione del metodo. Supponiamo di avere un file di testo contenente la frase: "CIAO MAMMA". Usando una codifica UTF-8 per rappresentare questa stringa, occorrerebbero 8 bit (1 byte) per ogni carattere, compreso lo spazio, per un totale di 10 byte (80 bit):
43 (C) 49 (I) 41(A) 4F(O) 20 (spazio) 4D (M) 41 (A) 4D (M) 4D (M) 41 (A)
L'algoritmo di Huffman si basa sul conteggio della frequenza di ogni carattere nella stringa. Nel nostro caso abbiamo:
C: 1 volta I: 1 volta A: 3 volte O: 1 volta spazio: 1 volta M: 3 volte
A questo punto vanno individuate i 2 caratteri con minore frequenza. Nel nostro caso, le lettere con minore frequenza sono ad esempio la C e la I (o anche la C e lo spazio oppure la I e lo spazio: qualunque scelta va bene: i codici prodotti sono diversi ma la compressione è identica). Ora rappresentiamo queste due lettere (C+I) usando un nodo in un albero, come mostrato in figura:
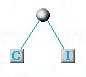
Nel nostro schema delle frequenze, la C e la I saranno d'ora in avanti rappresentate come un unica lettera e con una frequenza che sarà la somma delle loro frequenze: (C+I: 2 volte). Con questa notazione i simboli e le relative frequenze nella nostra stringa sono:
C+I: 2 volte A: 3 volte O: 1 volta spazio: 1 volta M: 3 volte
Ora troviamo nuovamente i due caratteri con minore frequenza (O e spazio) e raggruppiamoli in un nodo, come prima:
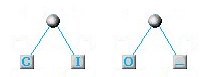
L'elenco delle frequenze, aggiornato tenendo conto del raggruppamento O+spazio è il seguente:
C+I: 2 volte A: 3 volte O+spazio: 2 volte M: 3 volte
A questo punto cerchiamo ancora le 2 lettere con minor frequenza e vediamo che si tratta dell'accoppiata C+I e O+spazio per cui il nuovo nodo sarà schematizzato usando i nodi creati in precedenza:
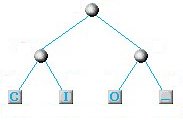
Lo schema delle frequenze diventerà a questo punto il seguente:
C+I+O+spazio: 4 volte A: 3 volte M: 3 volte
Prendiamo ancora una volte le 2 lettere di minor frequenza che adesso sono la A e la M:
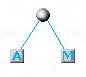
Lo schema delle frequenze a questo punto si è ridotto a solo due elementi:
C+I+O+spazio: 4volte A+M: 6 volte
Dovendo prendere i due caratteri con minor frequenza non ci rimane che selezionare gli unici due nodi rimasti e concludere finalmente il nostro albero:
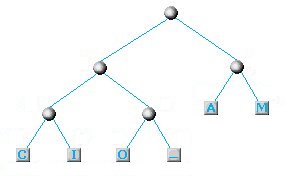
Una volta creato l'albero, bisogna associare alla biforcazione in due rami dopo ogni nodo un bit (0 o 1). E' possibile associare lo 0 a tutti i rami di sinistra e 1 a tutti quelli di destra. E' possibile anche fare il contrario senza compromettere il risultato finale. Nel nostro caso scegliamo lo 0 a sinistra e l'1 a destra ed ecco il risultato finale:
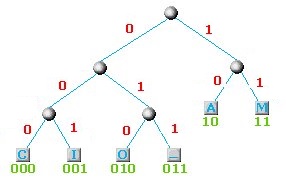
Il codice associato a ogni carattere è dato dalla sequenza di 0 e 1 che si incontrano per raggiungere il carattere partendo dalla radice dell'albero, come mostrato in figura.
Volendo scrivere "CIAO MAMMA" con i codici Huffman del nostro esempio otterremo la seguente sequenza di bits: 000001100100111110111110. In questo modo la stringa occupa solo 24 bit (3 byte) contro gli 80 bit (10 byte) della codifica UTF-8.
Tuttavia bisogna considerare il fatto che per interpretare un file codificato con l'algoritmo di Huffman occorre conoscere il codice: infatti la codifica usata per ogni file non è standard, ma dipende dalla frequenza (probabilità) dei singoli caratteri nel file. In pratica il file codificato deve contenere anche una tabella con la traduzione del codice, affinché chi riceve il file possa decodificarlo. Questa tabella ovviamente occupa spazio e dunque la codifica Huffman diventa conveniente solo quando il file da comprimere è di grandi dimensioni, per cui lo spazio occupato dalla tabella di conversione può essere trascurato.
Una caratteristica particolare di questo algoritmo è che il codice ottenuto per ogni singola lettera non è un prefisso di un altra lettera. Nel nostro esempio, la A ha il codice 10 e nessuna altra lettera ha una codifica che comincia con 10 (lo stesso ovviamente vale per tutte le altre lettere che abbiamo codificato). In questo modo leggendo la stringa di 24 bit che abbiamo ottenuto in precedenza, possiamo riconoscere le singole lettere senza bisogno di un separatore tra di loro.
In generale un codice viene detto prefisso, se è possibile decodificare correttamente un codice, poiché nessun simbolo del codice è prefisso di un'altro simbolo. Solo usando un codice prefisso è possibile realizzare una codifica a lunghezza variabile (altrimenti non sarebbe possibile separare un carattere da un altro, dal momento che tutti hanno una lunghezza di codice diversa).
Sito realizzato in base al template offerto da
http://www.graphixmania.it
